|
|
|
Введение в теорию компиляции. И выведение из неё...В прошлой статье мы логически рассмотрели почему абстрактный класс не может быть интерфейсом... и как этот недостаток можно было бы победить. Сегодня мы рассмотрим то же - но на совсем иной понятийной базе. Давайте вспомним существо наших изысканий. Первое - мы захотели, чтобы спецификации статического типа, предъявляемые "при сборке сервера" отличались от спецификаций типа, предъявляемых "при сборке клиента". Мы выделили список методов доступа к объекту, влияющий и на клиент и на сервер, и выделили прочие части конструкции сервера, влияющие только на сервер. Второе - пользуясь списком методов, который мы упаковали в абстрактный класс, мы получили вполне работающий доступ клиента к серверу. Третье - мы не смогли решить проблему первоначального создания этого объекта клиентом - ни прямо в своем коде, ни косвенно - посредством изобретения специальной функции в составе сервера и хитрой системы именования. Мы решили её только при помощи "виртуальных абстрактных классов". Почему? Здесь выяснились некоторые тонкие технологические подробности, которые, вероятно не все читатели смогли осилить в их абстрактном изложении. Поэтому сегодня мы, в общем-то, перескажем рассылку прошлую, но - в понятных терминах низкоуровневого программирования. Надо ли это? А как же! Программостроение - область человеческой деятельности, которой уже более пятидесяти лет. Учитывая, что в нашей сфере год эволюции идет за три, а то и за пять, от своих истоков мы ушли очень далеко. Выросло поколение программистов, которые весьма гордятся тем, что им приходится работать на языках высокого и очень высокого уровня, считающих знание Ассемблера и команд машины - знанием второго сорта, а то даже и вчерашним днём… А правилен ли такой взгляд? За последние две тысячи лет в медицине тоже достигнут значительный прогресс. То, было неизлечимо двести и кроваво резалось еще двадцать лет назад теперь часто можно вылечить бескровно, а то и вовсе консервативно. Только значит ли это, что современный хирург может позволить себе плохо знать "что у человека внутри"? Ведь изменилась только медицина, изменения же в "конструкции человеческого организма" как-то мало заметны... С нашими программами дело обстоит абсолютно так же. Изменились лишь технологии создания программ. Но природа что программиста, что его творения остаётся всё той же. Конечно, современный программист теперь может за неделю в одиночку написать то, что еще десять лет назад разрабатывалось целой командой по полгода и более. Но ведь "программист внутри" за пятьдесят прошедших лет не изменился? И сами программы - не изменились, они как были так и остались управляющими последовательностями машины фон Неймана. Их анатомия остается всё такой же, описанной в уже классических теперь трудах отцов-основателей ВТ. Так почему бы нам не рассмотреть всё сформулированное нами ранее в терминах нашего же профессионального языка? Для чего? Для всё для той же самой цели - точного понимания, "что у COM внутри". Ведь COM - двоичная технология. При всём горячем желании заинтересованных сторон исходные тексты программ в COM не распространяются. Взаимодействие своей сочиняемой программы приходится организовывать с двоичным компонентом. И очень нужно точно быть уверенным, что вы организуете именно то, что на самом деле должно быть. Начнём, естественно, с самого начала - программа, которую видит процессор есть последовательность двоичных чисел - команд процессора. Одну за одной он выбирает команды и совершает действия в них закодированные. Но это вовсе не означает, что двоичный файл, содержащий программу в машинных кодах, внутри никак не структурирован, что он представляет собой кусок просто "управляющей ленты" и только. Схематически конструкция загружаемого модуля (любой машины!) показана на рис.3: 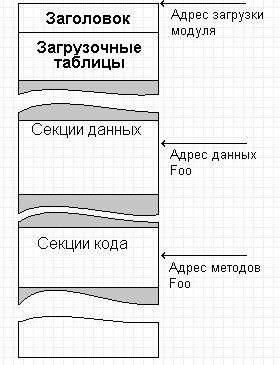 Рис 3. Схема устройства двоичного исполняемого модуля Можно видеть, что модуль имеет секционированную структуру - в нём есть заголовок, таблицы и секции (сегменты). Заголовок - служебная информация, описывающая загрузчику операционной системы с чем он имеет дело, как данный модуль должен загружаться в память и настраиваться для того, чтобы он мог быть выполнен. Таблицы - аналогичная информация, описывающая требования к окружению - какие ещё модули должны загружаться, чтобы данный мог выполняться, либо, наоборот, что данный модуль может предоставить в распоряжение других модулей. А вот секции - секции и есть собственно "части тела" нашей программы. Необходимость секционирования связана с тем, что двоичные данные имеют разную семантику - часть двоичных чисел действительно описывает "данные", а часть - команды процессора. Поскольку процессор "просто выполняет команды", то он не может отличить является ли двоичное число кодом команды программы или же - обрабатываемыми программой данными. Поэтому все данные собираются в один сегмент, а все команды - в другой. Сказанное - только очень примитивная иллюстрация, существует еще немало причин, по которым и данные и код должны быть структурированы по секциям и далее. Поэтому в составе исполняемого модуля обычно содержится несколько секций данных разного сорта и несколько секций кода, но для нас сейчас важно одно - данные и код на самом деле "разложены по разным карманам", они на стороне процессора не "прослаиваются" и вместе никогда не располагаются. А вот на стороне программиста, в языке высокого уровня на котором он пишет программу, ситуация обратна - в его тексте данные и код группируются вместе, "прослаиваются" и следуют логике мысли программиста, а не семантике двоичных данных. Ввиду чего у программиста, не знающего истинного положения вещей, могут возникать некоторые иллюзии, изживаемые обычно долгими часами бесплодной отладки… Но на рисунке показано, что объект класса Foo будет разложен на "данные - отдельно, методы - отдельно", каким бы образом в исходном тексте что ни определялось. Перевод программы из языка программиста на язык процессора выполняет специальная программа - транслятор. Транслятор принимает исходные предложения, записанные программистом, анализирует их и заменяет конструкции программиста равносильными конструкциями процессора. При этом транслятор ведет свои внутренние таблицы, в которых запоминает пары - "идентификатор - адрес двоичной конструкции". Всякий раз, когда в исходном тексте программист ссылается на идентификатор, транслятор на стороне процессора подставляет адрес из своей таблицы (называемый в таком случае ссылкой), соответствующий этому идентификатору. Поскольку мы так лихо конспективно разобрались с "теорией синтаксического анализа, перевода и компиляции", посмотрим, как бы мог транслятор обрабатывать нашу программу - класс сервера Foo и его примитивного клиента, которые мы определили в статье Откуда суть пошли интерфейсы программные. Соответствующий процесс показан на рис. 4: 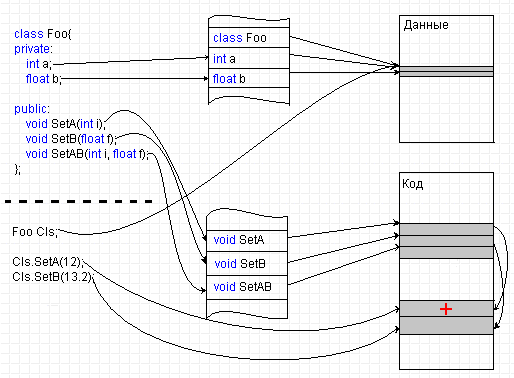 Рис 4. Схема построения исполняемого модуля Слева на рисунке показаны предложения исходного текста. Справа - секции кода и данных формируемого исполняемого модуля. Ясности существа ради предполагается, что у нас нет линковки и транслятор сразу строит не объектный, а исполняемый код. Посередине изображены некоторые таблицы транслятора - таблица смещений данных и таблица смещений кода. На самом деле транслятор не занимается немедленным переводом, он еще проверяет и синтаксическую правильность конструкций, поэтому внутренних таблиц транслятора будет побольше, и связей между синтаксическими конструкциями, которые учитывает транслятор, тоже значительно больше. Но нам для иллюстрации принципа это совершенно неважно. Итак, на вход транслятору попало описание нашего класса Foo. Транслятор проанализирует текст и где-то там себе отметит, что класс Foo состоит из двух элементов данных и трёх элементов процедур. Если они синтаксически правильны, то транслятор заполнит идентификаторами свои таблицы и расставит адреса данных класса относительно начала класса. Никакого кода здесь не порождается - вы знаете, что описание класса предназначено только транслятору. Транслятор двигается дальше и видит в тексте модуля определения методов класса. Здесь они особо не показаны - только из соображений экономии площади рисунка. Располагаются они в месте, обозначенном жирным пунктиром - там же, где и другие конструкции программы. Ничего особенного в них нет, это - просто функции, связанные с классом. Методы - порождают код, поэтому транслятор в таблице смещений кода подставит в пару "идентификатор метода - адрес точки входа в него" адрес и откомпилирует текст, разместив команды в секции кода. Т.к. методы пока ниоткуда не вызываются, то это - тоже пока всё. Дальше транслятор встречает определение объекта класса Foo Cls. Это предложение требует создать объект, т.е. отвести память под него и вызвать конструктор. Трансляция в этом и состоит - в сегменте данных транслятор отводит память и в таблице смещений данных помечает адреса, по которым он фактически разместил объект (вызов конструктора нас сейчас не интересует, а потому - пропускается). Ещё дальше - предложение Cls.SetA(12). То самое предложение, ради рассмотрения трансляции которого всё это и написано! Трансляция состоит в вызове метода SetA в применении к объекту Cls. Перед кодогенерацией транслятор, конечно, убедится, что вызвать метод не запрещено правилами видимости и разделения доступа, что метод объекта Foo применяется действительно к экземпляру объекта Foo и т.д. - все эти ограничения являются синтаксическими, они не влияют на генерацию кода. А вот дальше начинается интересное - транслятор построит вызов CALL <адрес метода из секции кода> и передаст ему в качестве параметра <адрес объекта из секции данных>. Точнее, это будет пара примерно таких команд: PUSH <адрес объекта из секции данных> CALL <адрес метода из секции кода> На рисунке место, где компилятор будет их размещать обозначено плюсиком красного цвета. Обратите внимание - то, что объект из секции данных семантически соотносится с методом из секции кода нигде не отмечено - это знает только транслятор из собственных своих таблиц. Это он сам просто непосредственно подставляет в код адреса. Элементы же данных "сами" ничего не знают, где располагаются соответствующие им методы, а методы - не знают, где располагаются "их" элементы данных. Когда транслятор закончит свою работу и завершится, таблицы эти будут забыты, и никто не узнает, каким там был объект Foo, но останется правильно сочинённая программа. Для проектного программирования нам больше ничего и не требовалось - всё работает так, как было описано на языке высокого уровня. Здесь должно также быть понятно, чем должен бы являться и чисто абстрактный невиртуальный класс (если бы таковой в языке C++ существовал) - он вообще ничего не порождал бы в коде, но он должен был бы заполнить таблицы транслятора, когда транслятор начинал разбор методов классов от него произведённых. И если транслятор углядел бы при этом несоответствие абстрактного класса производному от него - должна была возникнуть синтаксическая ошибка. И только! Однако, функциональность такого класса разработчики языка сочли избыточной - зачем, если всё то же, плюс еще кое-что полезное делает и виртуальный класс? И в языке в качестве абстрактного типа остался только виртуальный класс, что нисколько не вредит "потребительским качествам языка C++", но несколько затрудняет объяснение этой тонкой разницы для программистов не знающих Ассемблера. Из описанной же схемы ясно следует, что при компонентной конструкции программ клиент, вызывающий <адрес объекта из секции данных> никак не сможет узнать <адреса объекта из секции кода> - соответствующих таблиц-то связывающих одно и другое уже и нет. Поэтому решение проблемы "как получить адрес метода моего класса" должно быть перенесено с компилятора на сам объект, в его составе должна появиться особая таблица - таблица, в которой находятся адреса методов, которые может вызывать клиент. Мы говорили в прошлый раз, что это - специальный указатель на функцию, генерируемый компилятором в составе статического типа, как только компилятор видит слово virtual в описании метода. Более точно ситуация обстоит следующим образом - компилятор генерирует так называемую "таблицу виртуальных функций" (ее аббревиатура называется Vtbl), таблицу указателей по числу виртуальных методов, описанных в данном статическом типе. А в составе статического типа появляется указатель на эту Vtbl. Соответствующая микроархитектура показана на рис 5:  Рис 5. Двоичная микроархитектура объекта имеющего виртуальные методы Вы видите, что в составе одного только объекта данных, входящего в состав статического типа теперь имеется и информация о методах этого объекта - адреса точек входа в них. А сам объект данных состоит из структуры данных и служебной таблицы Vtbl. Указатель на Vtbl в составе объекта данных генерируется компилятором всегда на одном и том же месте, поэтому просто знания того, что у класса должна быть Vtbl достаточно, чтобы компилятор правильно на неё сослался. Сама же Vtbl есть не что иное, как двоичная структура времени выполнения, соответствующая виртуальному абстрактному классу. Словом, для того, чтобы знать и данные объекта и его методы нам теперь вполне достаточно знать только указатель на сам объект, на рисунке это адрес "объекта Cls статического типа Foo". А для того, чтобы знать только методы объекта Cls нам достаточно извлечь из него ссылку на Vtbl. И сделать это можно и на клиентской стороне ничего не зная о данных, составляющих сам объект сервера. Нужно так же сказать - на рис. 5 изображена совершенно точная двоичная структура "объекта экспонирующего интерфейс" на которой и построен COM. Единственная возможная здесь неточность - в какой именно памяти располагаются и сам объект данных и Vtbl класса. Здесь нарисовано, что они располагаются в статической памяти модуля, хотя это бывает (и значительно чаще!) и не так. Отметим - предложенного решения вполне достаточно: компилятор на клиентской стороне всё построит правильно. Соединённая архитектура клиент-серверного взаимодействия с использованием такого механизма на нижнем уровне показана на рис. 6: 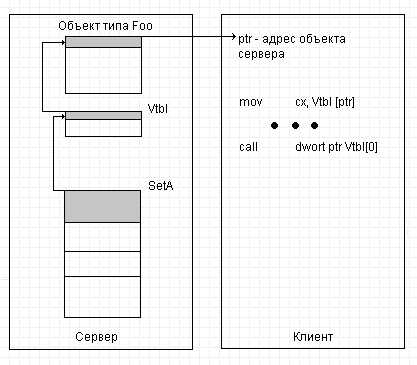 Рис 6. Клиент-серверное взаимодействие посредством Vtbl На этом рисунке показано, как имея указатель ptr на объект класса Foo компилятор в теле клиента будет вызывать метод SetA. Весь вызов сводится, по сути, только к двум командам процессора - извлечению из ptr ссылки на Vtbl и косвенному переходу по адресу в Vtbl. Там, где изображено жирное отточие компилятор вставит команды, соответствующие передаче аргументов вызываемому методу - они ничем не отличаются от команд, которые генерируются и при вызове "обычного" метода. Обратите внимание - мы полностью добились того, чего хотели. Во-первых, между клиентом и сервером у нас "нет ничего общего", кроме описания таблицы виртуальных методов (виртуального чисто абстрактного класса). И клиент и сервер теперь могут разрабатываться, видоизменяться и компилироваться совершенно независимо. Но, как только изменится описание этой таблицы - и клиент и сервер должны быть пересобраны оба. Во-вторых, эта самая таблица является в чистом виде интерфейсом - она не описывает "что", это сообщает ссылка на объект - указатель, получаемый от сервера. Зато именно она описывает "как" - адреса-то самих вызываемых из секции кода методов берутся из нее самой. В-третьих, эта самая таблица - вполне "осязаемая" сущность, она существует во время исполнения и может быть перенумерована самостоятельным номером, так же, как мы нумеровали статические типы. В сущности, теперь мы располагаем всеми механизмами и микроархитектурными решениями для того, чтобы приступить к компонентному программированию. Чем со следующей статьи и займёмся...
Авторские права © 2001 - 2004, Михаил Безверхов Публикация требует разрешения автора |
|
 © 2000-2004 Клуб программистов developing.ru
© 2000-2004 Клуб программистов developing.ru