|
|
|
Память, как аппаратное устройствоЛюбая процессорная (микроконтроллерная) система устроена, в общем-то, одинаково. Существует устройство, называемое "процессор", которое умеет в самом общем смысле "перерабатывать информацию" - получая на вход информацию одну, на выходе оно создаёт информацию другую. Естественно, вполне детерминированную – алгоритм этого самого преобразования описывается "программой". Но для нас сейчас это не важно, сейчас нас интересует ответ только на один вопрос – как именно "процессор" обменивается с "внешним миром". И принцип на котором это взаимодействие построено коротко именуется "архитектура общая шина". Он изображён на рис.1, на котором показано три устройства – процессор и два ОЗУ : 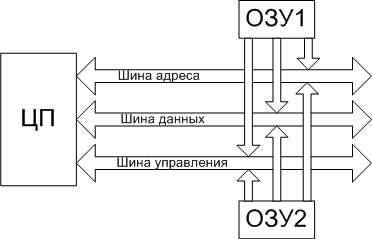 рис 1. Схема архитектуры "общая шина" Видно, что в составе этой шины выделяется три группы линий (которые есть не что иное, как самые обычные электрические проводники) – "шина управления", по которой процессор подаёт сигналы управления, "шина данных", по которой передаются двоичные числа, которые считаются "данными" и "шина адреса", по которой передаются такие же числа, но они считаются "адресом". Разрядность шины (число линий, по которым одновременно передаются биты) обычно совпадает с разрядностью самого процессора. Так, у 32-хразрядного процессора обычно же и 32-хразрядная шина, хотя можно построить и иную конфигурацию. Физическое ОЗУ (Random Access Memory, RAM ) представляет собой компонент, "разделёный" на некоторое количество ячеек, которые могут хранить в себе комбинации битов. Ячейки отличаются друг от друга номером, который ОЗУ воспринимает с "шины адреса", а связь содержимого ячейки с внешним миром осуществляется посредством "шины данных". Принципиальная схема организации ОЗУ приведена на рис.2:  рис 2. Принципиальная схема организации ОЗУ "Цикл памяти" в общем виде выглядит так. Процессор, желающий прочитать содержимое ячейки с адресом M устанавливает этот адрес на "шину адреса" и ставит на "шину управления" сигнал "чтение". ОЗУ , получив этот сигнал, выставляет содержимое своей ячейки с таким номером на "шину данных" и ставит на шину управления сигнал "готово". Получив этот сигнал процессор воспринимает состояние шины данных и убирает сигнал "чтение". Запись в ОЗУ происходит аналогично – процессор ставит на шину данных число, подлежащее записи, на шину адреса – номер записываемой ячейки, а на шину управления – сигнал "запись". ОЗУ , получив этот сигнал, воспринимает состояние шины данных и сохраняет его в ячейке с номером M . Здесь мы не будем касаться вопроса, как процессор "считывает байт", когда ширина шины данных фактически – несколько байтов. Не очень грубое для программиста допущение состоит в том, что из ОЗУ всегда считываются столько байтов, сколько составляют ширину шины, а из них процессором выбирается только один... Естественно, что количество ячеек в одном устройстве памяти – ограничено. Физически это выражается в том, что не всякое возможное на шине адреса число приведёт к "срабатыванию ячейки" - возможно, что ячейки с таким адресом просто физически не существует (на приведённом рис. 1 предполагается, что часть доступного диапазона адресов обслуживается одним ОЗУ , а часть – другим, они "срабатывают" на разные адреса). Обычно диапазон "вообще возможных адресов" значительно больше того диапазона адресов, на которое в состоянии откликнуться "физическое ОЗУ " - сравните, например 2 32 (4Гб) и 2 27 (128Мб). Причина этого – исключительно экономическая и техническая. Память и стоит каких-то денег и занимает какой-то объём. Возможность же процессора адресовать больше – в данном случае есть не что иное, как нереализованный резерв. Описанную модель обращения с физической памятью легко "поднять выше" - на уровень программиста. Ведь "читать слово" и "писать слово" - разные команды процессора, это его дело какие числа на какие шины ставить, программист только снабжает процессор эти самым "адресом" прямо или косвенно указывая его в самой команде. А модель набора ячеек как раз и получается в виде непрерывной строки с диапазоном адресов от какого-то "младшего" до какого-то "старшего" - программисту-то какое дело ОЗУ1 хранит данную ячейку или ОЗУ2 ? И в ранних процессорных системах именно так оно и было – адреса, которые программист указывал в командах были именно теми, которые процессор выставлял на шину адреса. И, хотя программист мог, например, в качестве адреса указать число 2 21 он этого не делал, ибо знал, что последняя "срабатывающая" ячейка располагается по адресу 2 20 -1. Попытка обратиться по адресу большему приносила либо "мусор", либо прерывание – это зависело от конструкции машины. Операционная система MS DOS – как раз и есть пример такой программы, работающей с процессором в т.н. "режиме реального адреса". Шло время, процессоры становились мощнее, программы – требовали всё большего объёма памяти. Это – совершенно закономерный процесс, поскольку процессор, могущий перерабатывать большой объём информации нет смысла укомплектовывать малым объёмом памяти – чтобы много информации перерабатывать надо прежде всего уметь много информации и хранить. И - мощность процессоров росла гораздо быстрее, чем возможность технологии производить большие и дешёвые ОЗУ . "Узким местом" всей процессорной системы стала физическая память. В этих обстоятельствах внимание архитекторов обратилось к неиспользуемому резерву – если процессор по ширине своей шины может адресовать 4Г разных ячеек, то нельзя ли каким-нибудь способом сделать так, что они "как бы есть", хотя на самом деле их и нет? Т.е. речь шла о механизме (архитектурном решении), который бы позволил эмулировать больший объём памяти, чем тот объём физических ОЗУ , которым на самом деле располагала машина. Понятно, что такую иллюзию нужно было создать только у самого "источника адресов" - у программы, обращающейся в память. Ведь если она сможет указать в команде (по другому задать адрес программа не может) число 2 30 (1Г) и получить осмысленное значение данных, то она по прежнему может считать, что у неё есть ОЗУ объёмом 1Г, какая ей разница, какое аппаратное устройство на этот адрес "срабатывает" и как именно? Поэтому речь шла прежде всего об аппаратном решении – в описанной выше архитектуре памяти "что поставил - то и прочитал", а для создания требуемой иллюзии нужно было, чтобы адрес, который задаётся в команде процессора и адрес, который процессор ставит на шину адреса – как-то соотносились друг с другом, но были разными . И это преобразование одного в другое должно было быть однозначным, незаметным для программы и очень быстрым – ведь такое преобразование должно было применяться к каждому адресу, выставляемому процессором! Общий принцип архитектурного решения, удовлетворяющего сформулированным требованиям можно описать так. В процессоре должен быть особый узел – блок преобразования адреса ( БПА ). Программа указывает свой адрес (его теперь естественно назвать "логическим"), он попадает в этот блок, блок что-то с ним делает такое, чтобы из этого адреса сделать "физический" - адрес заведомо существующей в системе физической ячейки памяти, и лишь затем такой преобразованный адрес попадает на шину адреса. Шина данных – не изменяется. А схема "цикла памяти" расширяется на фазу преобразования адреса. Такой режим работы процессора получил название "режим виртуального адреса". А как можно выполнить такое преобразование? Когда логический адрес соответствует какому-то физическому – всё понятно. Например, всякий логический адрес мы можем складывать с константой (операция быстрая, делается "на лету") – диапазон физических адресов просто сдвинется (будет отличаться от тех адресов, что указаны в командах), но соответствие-то останется. А ведь мы хотим раздвинуть диапазон! Это означает, что когда-то на вход преобразователя адреса придёт такой логический адрес, которому соответствует несуществующая физическая ячейка. Верно. В таком случае процессор должен сделать два дополнительных действия – во-первых, он должен вызвать особое прерывание "запрашиваемой памяти – нет", т.е. вызвать специальную программу-обработчик. Во-вторых, он должен "открутить назад" свой счётчик команд – прерывание вызвано считанной командой, которая попыталась обратиться к несуществующим данным. В "нормальной системе" такое событие – фатально, а здесь процессор должен "сделать вид" что он эту самую команду только собирается исполнить. Что должен делать обработчик этого прерывания? Он должен... обеспечить ранее не существовавшие, а теперь понадобившиеся данные. Как??? Например, взять и загрузить их откуда-нибудь на то самое место физической памяти, которое действительно есть, сообщить в блок преобразования адреса, что этому самому запрошенному "логическому адресу" теперь соответствует вот такой физический и ... просто вернуть управление. Поскольку процессор перед этим свой счётчик команд "открутил назад", то, после возврата из прерывания, он повторно выбирает ту самую команду, которая прерывание вызвала - теперь эти данные уже существуют – и исполнение программы продолжится как ни в чём ни бывало. Вот и почти всё аппаратное решение! Тем не менее, в нём пока непонятны две вещи – во-первых, сам алгоритм преобразования адреса. Во-вторых – откуда загружать эти "виртуальные данные" и как. Делать это побайтно и пословно – фактически иметь "запасное ОЗУ " (которого мы как раз иметь-то и не хотим), поскольку единственной просматриваемой альтернативой ОЗУ (другим устройством, умеющим хранить данные – чудес на свете не бывает) является диск, а он – устройство блочное, байты адресовать не умеет. Обе проблемы решаются в комплексе – ведь и преобразование адреса не может быть выполнено "с точностью до байта" - это тоже означает, что для однозначного преобразования нужно иметь "второй комплект байтов". Поэтому преобразование адреса производится по таблице – выборка из таблицы ничуть не более медленная операция, чем сложение. А само преобразование логического адреса делается так, как показано на рис. 3: 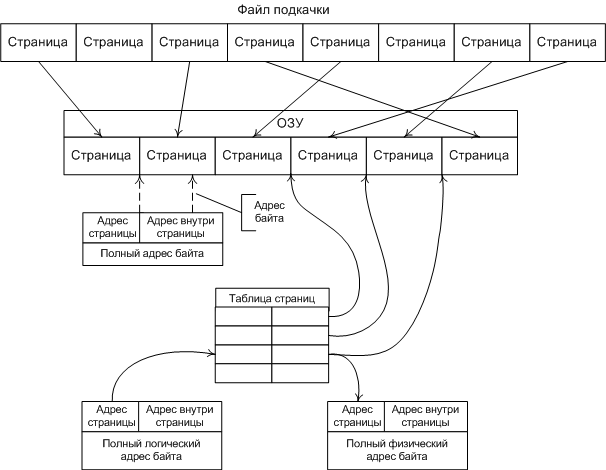 рис 3. Схема преобразования логического адреса в физический Логический адрес делится на две части, простым проведением границы между битами. Старшая часть адреса называется "адрес страницы", а младшая "адрес внутри страницы". Страница и есть та самая порция информации, которую обработчик прерывания "несуществующие данные" (точное название этого прерывания - "страничная ошибка") загружает с диска в ОЗУ . Её размер не должен быть очень маленьким, поскольку иначе "страничная ошибка" будет возникать часто и машина просто будет гонять данные из памяти на диск и обратно. Но, с другой стороны, её размер не должен быть и слишком большим – на загрузку тратится время. А программе на странице может понадобиться всего-то сотня байт, а потом она перейдет по другому адресу, который соответствует уже другой странице – и снова загрузка. В блоке преобразования адреса ведётся специальная таблица, в которой адресу страницы (старшей части логического адреса) соответствует реальный адрес физической памяти, где эта страница расположена. Каждая строка этой таблицы – адрес загруженной в ОЗУ страницы, т.е. страницы физически доступной в данный момент для обращения. Преобразователь адреса "режет" поступивший логический адрес на части "страничный" и "внутри страницы" и пытается найти в этой таблице соответствие – какой же физический адрес соответствует данному страничному. Если такое соответствие находится, то к физическому адресу страницы прибавляются младшие биты "адрес внутри страницы" и получается адрес физического байта, который в данный момент соответствует данному логическому адресу – адресация возможна и проходит, как и в системе с "реальным адресом" - программа и не узнает, что в действительности "срабатывала" ячейка не с тем адресом, который был указан в программе. Если же соответствие не находится, т.е. обнаруживается, что нужная страница не значится в таблице как "загруженная", блок преобразования адреса возбуждает прерывание "страничная ошибка" и сообщает обработчику какую страницу необходимо загрузить. Обработчик должен: отыскать на диске ту самую страницу, найти ей место в физической памяти, загрузить страницу и исправить в блоке преобразования адреса адрес страницы в таблице. Когда в физической памяти есть не занятые страницы – всё просто. А если всё место уже занято другими страницами? Тогда обработчик должен какую-то страницу вытеснить – записать её на диск с тем, чтобы на её место вписать нужную. Какую? Мнения на сей счёт могут быть различными, но наиболее употребительный алгоритм вытесняет ту страницу, к которой давно не было обращений. С этой целью в "страничной таблице" ведётся и счётчик времени обращения – исключительно аппаратное решение, которое не удлиняет цикла памяти. Когда обработчик вернёт управление процессор вновь исполнит ту же команду, попытка обращения которой к памяти оказалась неуспешной, но в блоке преобразования адреса требуемая страница уже будет числиться "загруженной" - обращение к памяти пройдёт успешно. Поэтому общая схема программно-аппаратного механизма, обеспечивающего описанным способом создание иллюзии наличия большей оперативной памяти, чем есть в действительности, приведена на рис. 4: 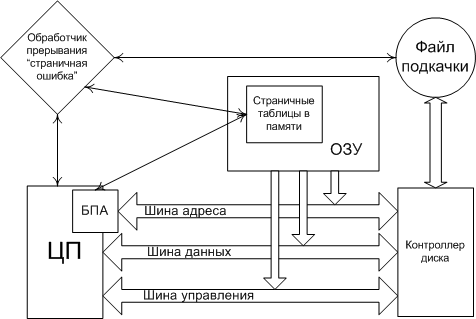 рис 4. Общая схема механизма виртуальной памяти Первое, что сразу бросается в глаза – без диска (без хранилища вытесненных страниц) эта схема не работает вообще. Где-то нужно иметь этот самый "файл подкачки". Второе – объём реального ОЗУ влияет на быстродействие машины, поскольку чем он больше, тем реже приходится обращаться к загрузке страниц. А вот объём действительно доступной памяти уже не определяется ОЗУ – он определяется именно объёмом "файла подкачки". И может быть сделан хоть на весь доступный диапазон адресов - 4 Гб для 32-хразрядного адреса. Именно это обычно и называется "механизм виртуальной памяти". Но то, что приведено выше – только принципиальная схема. Действительность ещё сложнее – поскольку современные процессоры изначально ориентированы на "многозадачность" к схеме виртуальной памяти предъявляется и ещё одно требование – разные процессы должны обладать разными "адресными пространствами", т.е. схема адресации физической памяти должна быть такой, чтобы ни при каких обстоятельствах один процесс не мог адресовать память, принадлежащую другому процессу. Хочется подчеркнуть – это требование не вытекает из требований ни к машине, ни к памяти, ни вообще к аппаратной части. Оно вытекает из существующей технологии создания надёжных программ, а машина – должна поддерживать его. Модель такой памяти предполагает, что один и тот же логический адрес со значением X , но порождённый в разных процессах, должен приводить на разные страницы физической памяти. Такой режим адресации процессора носит название "режима защищенного адреса", так что полное название режима в котором процессор может делать всё вышеупомянутое звучит как "режим защищённого виртуального адреса" - именно он и есть основной рабочий режим процессора под управлением современных операционных систем. Поэтому нарисованная на рис.4 схема усложняется. В блоке преобразования адреса (фактически, конечно, это хранится в некоторой статически распределённой области ОЗУ , той, которая никогда не участвует в страничном обмене) имеется не вообще одна таблица преобразования страничного адреса, а – ещё по одной таблице на процесс, в которых отмечается, какие страницы каким процессам принадлежат. И при переключении процессов эти таблицы в блоке преобразования адреса тоже переключаются. Фактически преобразование адреса и поиск нужной страницы происходят в два этапа – сначала выясняется является ли для данного процесса адресуемой запрашиваемая страница, а потом – где именно она расположена. Делается это аппаратно и элементы процессора, которые выполняют это сложное преобразование оптимизированы настолько, что физический адрес байта преобразователь вычисляет чуть ли не за такт до того, как получит себе на вход логический адрес подлежащий преобразованию. Так что вся эта сложность не приводит к уменьшению абстрактного быстродействия машины. Хотя, конечно, машина с виртуальной памятью в среднем работает медленнее, чем аналогичная машина с памятью исключительно реальной – на страничный обмен тратится время, которое недополучает исполняющаяся "программа пользователя". Ещё раз повторим – сказанное выше есть только близкая к реальному воплощению в существующих процессорах принципиальная схема. Более подробное и точное знание о том, как функционирует обозначенный механизм нужно немногим программистам, а они его знают и так. Для нас, обычных программистов, сказанное – только необходимое основание для того, чтобы перейти к собственно предмету данной статьи – как устроено в операционной системе использование описанных аппаратных возможностей и что оно даёт программисту, использующему, например, платформу Win32 .
Авторские права © 2001 - 2004, Михаил Безверхов Публикация требует разрешения автора |
|
 © 2000-2004 Клуб программистов developing.ru
© 2000-2004 Клуб программистов developing.ru